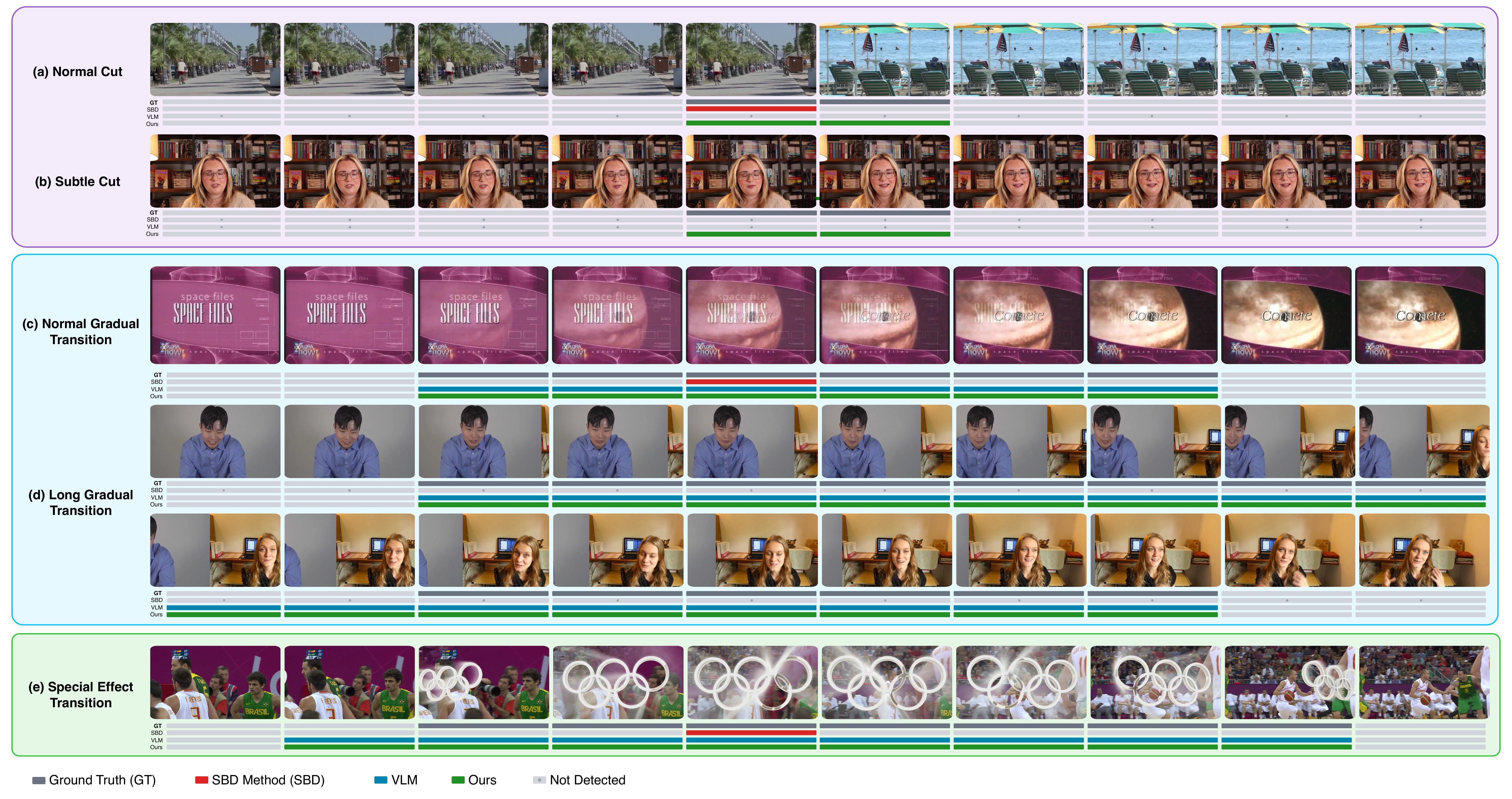
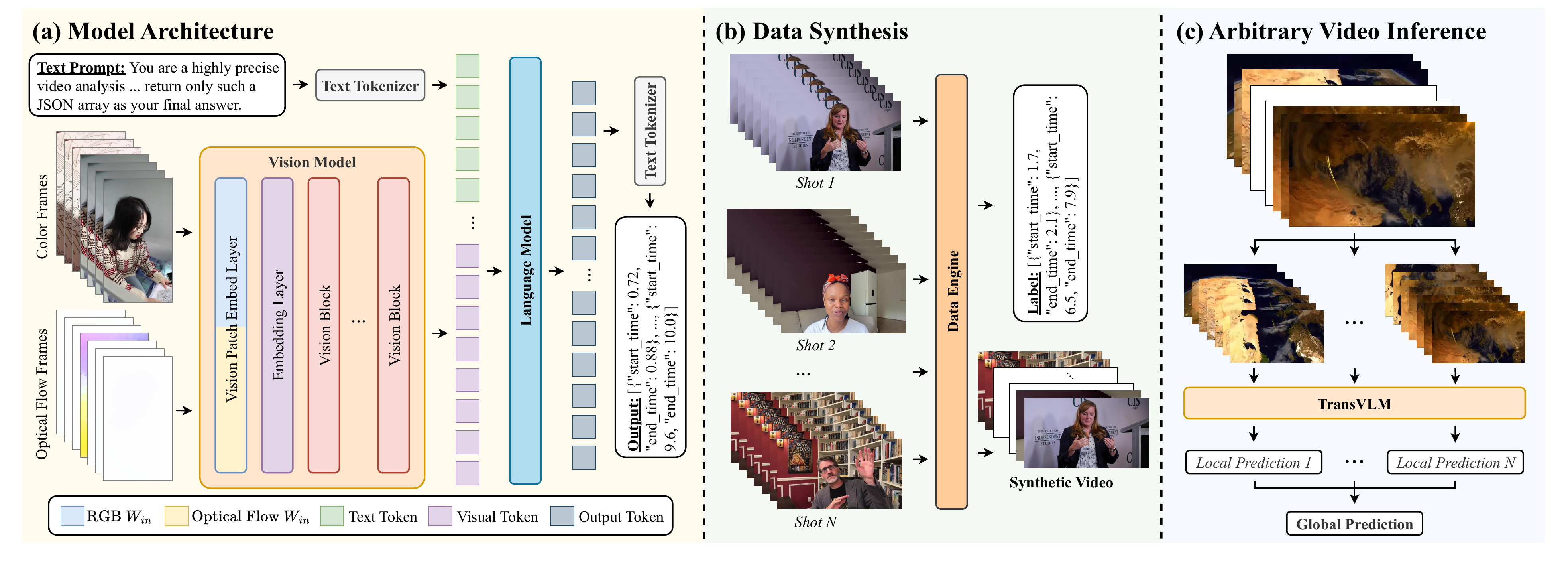
Comparison with Baselines
Evaluation Metrics
We propose a rigorous evaluation suite comprising both segment-level and frame-level
metrics, parameterized by a temporal tolerance τ (0.0 – 0.5 s) to handle
annotator subjectivity at gradual transition boundaries:
Segment F1 (instance retrieval),
Frame F1 (temporal coverage),
Absolute Boundary Error (ABE) in seconds, and
Real-Time Factor (RTF) for inference efficiency.
Quantitative Comparison
We compare TransVLM against five paradigms: PySceneDetect [8],
TransNetV2 [9], AutoShot [1],
Gemini series [10], and Qwen3-VL series
[2]. We report mean segment- and frame-level metrics across
the defined τ values. TransVLM substantially outperforms heuristic methods, specialized
networks, and significantly larger general-purpose VLMs.
Bold = best, underline = second-best.
| Method |
Public Data |
Synthetic Data |
RTF |
| Segment | Frame | ABE |
Segment | Frame | ABE |
| P | R | F1 |
P | R | F1 |
P | R | F1 |
P | R | F1 |
| PySceneDetect [8] |
| Adaptive | 0.656 | 0.716 | 0.684 | 0.645 | 0.372 | 0.457 | 1.93 | 0.924 | 0.172 | 0.290 | 0.922 | 0.036 | 0.069 | 0.28 | 0.09 |
| Content | 0.627 | 0.759 | 0.686 | 0.603 | 0.383 | 0.453 | 1.08 | 0.909 | 0.128 | 0.225 | 0.968 | 0.029 | 0.056 | 0.61 | 0.09 |
| Hash | 0.566 | 0.778 | 0.654 | 0.549 | 0.416 | 0.457 | 2.11 | 0.880 | 0.118 | 0.208 | 0.940 | 0.027 | 0.052 | 0.85 | 0.09 |
| Hist | 0.452 | 0.741 | 0.559 | 0.419 | 0.398 | 0.394 | 1.19 | 0.577 | 0.379 | 0.455 | 0.762 | 0.117 | 0.197 | 1.04 | 0.09 |
| Threshold | 0.364 | 0.031 | 0.057 | 0.306 | 0.014 | 0.027 | 3.08 | 0.773 | 0.039 | 0.074 | 0.749 | 0.008 | 0.016 | 1.46 | 0.09 |
| TransNetV2 [9] | 0.727 | 0.780 | 0.752 | 0.731 | 0.427 | 0.528 | 1.87 | 0.275 | 0.149 | 0.194 | 0.417 | 0.034 | 0.063 | 0.61 | 0.07 |
| AutoShot [1] | 0.707 | 0.804 | 0.751 | 0.709 | 0.440 | 0.532 | 1.78 | 0.379 | 0.248 | 0.299 | 0.530 | 0.058 | 0.102 | 0.51 | 0.03 |
| Gemini Series [10] |
| 2.5 Pro | 0.558 | 0.527 | 0.542 | 0.453 | 0.361 | 0.401 | 3.62 | 0.338 | 0.851 | 0.465 | 0.638 | 0.760 | 0.686 | 0.82 | 0.81 |
| 3 Pro | 0.527 | 0.573 | 0.549 | 0.469 | 0.343 | 0.393 | 2.18 | 0.479 | 0.768 | 0.588 | 0.711 | 0.482 | 0.568 | 0.88 | 1.32 |
| Qwen3-VL Instruct Series [2] |
| 4B | 0.235 | 0.088 | 0.124 | 0.134 | 0.174 | 0.148 | 55.00 | 0.717 | 0.306 | 0.428 | 0.458 | 0.618 | 0.525 | 8.88 | 0.31 |
| 8B | 0.222 | 0.297 | 0.246 | 0.132 | 0.307 | 0.184 | 34.39 | 0.586 | 0.597 | 0.591 | 0.741 | 0.204 | 0.315 | 1.60 | 0.34 |
| 32B | 0.309 | 0.473 | 0.370 | 0.214 | 0.279 | 0.241 | 3.96 | 0.895 | 0.623 | 0.735 | 0.911 | 0.361 | 0.516 | 1.35 | 0.98 |
| 30B-A3B (MoE) | 0.218 | 0.300 | 0.242 | 0.171 | 0.222 | 0.192 | 9.61 | 0.806 | 0.593 | 0.683 | 0.749 | 0.355 | 0.482 | 1.86 | 0.35 |
| Qwen3-VL Thinking Series [2] |
| 4B | 0.449 | 0.079 | 0.134 | 0.265 | 0.051 | 0.086 | 1.50 | 0.839 | 0.218 | 0.346 | 0.748 | 0.087 | 0.156 | 1.68 | 1.03 |
| 8B | 0.450 | 0.144 | 0.217 | 0.297 | 0.094 | 0.143 | 4.25 | 0.854 | 0.389 | 0.534 | 0.923 | 0.147 | 0.252 | 1.29 | 1.31 |
| 32B | 0.403 | 0.260 | 0.315 | 0.308 | 0.160 | 0.209 | 1.09 | 0.900 | 0.608 | 0.726 | 0.943 | 0.323 | 0.479 | 1.16 | 3.30 |
| 30B-A3B (MoE) | 0.374 | 0.217 | 0.275 | 0.291 | 0.127 | 0.175 | 0.98 | 0.890 | 0.610 | 0.724 | 0.915 | 0.331 | 0.485 | 1.18 | 0.92 |
| TransVLM (Ours) | 0.762 | 0.806 | 0.783 | 0.574 | 0.562 | 0.568 | 1.58 | 0.908 | 0.882 | 0.895 | 0.946 | 0.930 | 0.938 | 0.11 | 0.50 |
Per-τ Comparison & Curves
Use the panels below to inspect detailed per-method numbers across each dataset / temporal
tolerance τ, and visualize the corresponding metric curves as a function of τ.
In each per-τ table, bold marks the best result and underline marks the
second-best.